
Saturs
- Skeptiķu klubs
- Konvolucionālie neironu tīkli (CNN)
- Bez kļūdām, bez stresa - jūsu soli pa solim, kā izveidot programmatūru, kas maina dzīvi, neiznīcinot savu dzīvi
- Ilgas īslaicīgas atmiņas (LSTM) vienības
- Ģeneratīvie sacensību tīkli (GAN)
- Secinājumi

Avots: Vs1489 / Dreamstime.com
Izņemšana:
Vai "dziļā izglītība" ir tikai vēl viens nosaukums uzlabotajiem neironu tīkliem, vai arī tur to ir vairāk? Mēs apskatīsim nesenos sasniegumus dziļajās mācībās, kā arī neironu tīklos.
Skeptiķu klubs
Ja jūs, tāpat kā es, piederat skeptiķu klubam, jūs, iespējams, arī domājāt, kas ir visas satraukums par dziļu mācīšanos. Neironu tīkli (NN) nav jauns jēdziens. Daudzslāņu perceptrons tika ieviests 1961. gadā, kas nav precīzi tikai vakar.
Bet pašreizējie neironu tīkli ir sarežģītāki nekā tikai daudzslāņu perceptrons; viņiem var būt daudz vairāk slēptu slāņu un pat atkārtoti savienojumi. Bet turieties, vai viņi joprojām treniņos neizmanto backpropagation algoritmu?
Jā! Tagad mašīnu skaitļošanas jauda nav salīdzināma ar to, kas bija pieejams 60. vai pat 80. gados. Tas nozīmē, ka saprātīgā laikā var apmācīt daudz sarežģītākas neironu arhitektūras.
Tātad, ja koncepcija nav jauna, vai tas var nozīmēt, ka dziļa mācīšanās ir tikai steroīdu neironu tīklu kopums? Vai visas nepatikšanas ir saistītas tikai ar paralēlu aprēķināšanu un jaudīgākām mašīnām? Bieži vien, izskatot tā sauktos dziļās mācīšanās risinājumus, tas izskatās. (Kāda ir praktiskā neironu tīklu izmantošana reālajā pasaulē? Uzziniet 5 neironu tīkla lietošanas gadījumos, kas palīdzēs labāk izprast tehnoloģiju.)
Kā jau teicu, es tomēr piederu skeptiķu klubam, un parasti es atturos no vēl neatbalstītiem pierādījumiem. Vienu reizi atmetīsim aizspriedumus un mēģināsim padziļināti izpētīt jaunizveidotās metodes dziļā apmācībā attiecībā uz neironu tīkliem, ja tādi ir.
Padziļināti izpētot, dziļās mācīšanās jomā mēs atrodam dažas jaunas vienības, arhitektūru un paņēmienus. Dažiem no šiem jauninājumiem ir mazāks svars, piemēram, nejaušināšanai, ko rada pamešanas slānis. Daži citi tomēr ir atbildīgi par svarīgākām izmaiņām. Un, protams, vairums no viņiem paļaujas uz lielāku skaitļošanas resursu pieejamību, jo tie ir diezgan skaitļošanas ziņā dārgi.
Manuprāt, neironu tīklu jomā ir bijuši trīs galvenie jauninājumi, kas ir ievērojami veicinājuši dziļu mācīšanos, iegūstot tā pašreizējo popularitāti: konvolūcijas neironu tīkli (CNN), ilgtermiņa īstermiņa atmiņas (LSTM) vienības un ģeneratīvi pretstatīti tīkli (GAN) ).
Konvolucionālie neironu tīkli (CNN)
Dziļās mācīšanās lielais sprādziens - vai vismaz tad, kad pirmo reizi dzirdēju uzplaukumu - notika attēlu atpazīšanas projektā - ImageNet Large Scale Visual Recognition Challenge - 2012. gadā. Lai attēlus atpazītu automātiski, konvolucionālais neironu tīkls ar Tika izmantoti astoņi slāņi - AlexNet. Pirmie pieci slāņi bija konvolucionāri slāņi, dažiem no tiem sekoja maksimāli apvienojošie slāņi, un pēdējie trīs slāņi bija pilnībā savienoti slāņi, visi ar nepiesātinātu ReLU aktivizācijas funkciju. AlexNet tīkls sasniedza piecu labāko kļūdu līmeni par 15,3%, kas ir par vairāk nekā 10,8 procentpunktiem zemāks nekā otrajā vietā esošajam. Tas bija lielisks sasniegums!
Bez kļūdām, bez stresa - jūsu soli pa solim, kā izveidot programmatūru, kas maina dzīvi, neiznīcinot savu dzīvi

Jūs nevarat uzlabot savas programmēšanas prasmes, kad nevienam nerūp programmatūras kvalitāte.
Papildus daudzslāņu arhitektūrai lielākais AlexNet jauninājums bija konvolucionārais slānis.
Pirmais slānis konvolucionālajā tīklā vienmēr ir konvolucionālais slānis. Katrs neirons konvolucionālajā slānī ir fokusēts uz noteiktu ieejas attēla zonu (uztveres lauku) un caur saviem svērtajiem savienojumiem darbojas kā uztveres lauka filtrs. Pēc filtra, neirona pēc neirona slīdēšanas pa visiem attēla uztveres laukiem, konvolucionāra slāņa izeja rada aktivizācijas karti vai funkciju karti, ko var izmantot kā pazīmju identifikatoru.
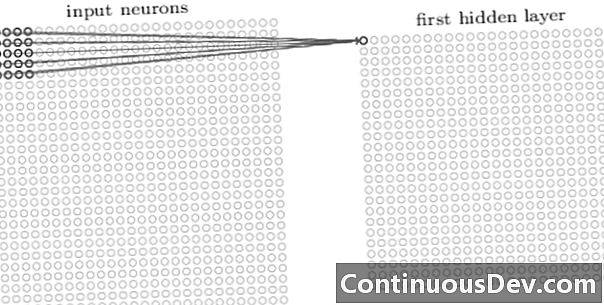
Pievienojot viens otram vairāk konvolucionāro slāņu, aktivizācijas karte no ieejas attēla var attēlot arvien sarežģītākas funkcijas. Turklāt bieži vien konvolucionālajā neironu tīkla arhitektūrā starp visiem šiem konvolucionārajiem slāņiem tiek sajaukti vēl daži slāņi, lai palielinātu kartēšanas funkcijas nelinearitāti, uzlabotu tīkla noturīgumu un kontrolētu pārmērīgu uzstādīšanu.
Tagad, kad mēs varam noteikt augsta līmeņa funkcijas no ievades attēla, tradicionālajai klasifikācijai tīkla galā varam pievienot vienu vai vairākus pilnībā savienotus slāņus. Šī pēdējā tīkla daļa ņem konvolucionāro slāņu izvadi kā ieeju un izvada N dimensijas vektoru, kur N ir klašu skaits. Katrs skaitlis šajā N dimensijas vektorā apzīmē klases varbūtību.
Dienas laikā es bieži dzirdēju iebildumus pret neironu tīkliem par to arhitektūras caurspīdīguma trūkumu un neiespējamību interpretēt un izskaidrot rezultātus. Mūsdienās šis iebildums tiek izvirzīts arvien retāk saistībā ar dziļajiem mācību tīkliem. Izskatās, ka tagad ir pieņemami tirgot melnās kastes efektu, lai panāktu lielāku klasifikācijas precizitāti.
Ilgas īslaicīgas atmiņas (LSTM) vienības
Vēl viens liels uzlabojums, ko rada dziļi mācoties neironu tīkli, ir redzams laika rindu analīzē, izmantojot atkārtotus neironu tīklus (RNN).
Atkārtoti neironu tīkli nav jauna koncepcija. Tie tika izmantoti jau deviņdesmitajos gados un tika apmācīti ar atpakaļprodukcijas laika gaitā (BPTT) algoritmu. Tomēr deviņdesmitajos gados tos bieži nebija iespējams apmācīt, ņemot vērā nepieciešamo aprēķina resursu daudzumu. Tomēr mūsdienās pieejamās skaitļošanas jaudas palielināšanās dēļ ir kļuvis ne tikai apmācīt RNN, bet arī palielināt to arhitektūras sarežģītību. Vai tas ir viss? Nu, protams, nē.
1997. gadā tika ieviesta īpaša neironu vienība, lai labāk risinātu attiecīgās pagātnes iegaumēšanu laika rindās: LSTM vienība. Izmantojot iekšējo vārtu kombināciju, LSTM vienība spēj atcerēties būtisko pagātnes informāciju vai aizmirst laikrindu nebūtisko pagātnes saturu. LSTM tīkls ir īpašs atkārtota neironu tīkla tips, ieskaitot LSTM vienības. LSTM bāzes RNN atlocītā versija ir parādīta 2. attēlā.
Lai pārvarētu ierobežotās ilgstošās atmiņas iespēju problēmu, LSTM vienības izmanto papildu slēpto stāvokli - šūnas stāvokli C (t) - atvasināts no sākotnējā slēptā stāvokļa h (t). C (t) apzīmē tīkla atmiņu. Konkrēta struktūra, ko sauc par vārtiem, ļauj noņemt (aizmirst) vai pievienot (atcerēties) informāciju šūnas stāvoklī C (t) katrā laika posmā, pamatojoties uz ieejas vērtībām x (t) un iepriekšējais slēptais stāvoklis h (t − 1). Katrs vārts izlemj, kuru informāciju pievienot vai dzēst, izejot vērtības no 0 līdz 1. Reizinot vārtu izvadi ar šūnas stāvokli C (t − 1), informācija tiek izdzēsta (vārtu izeja = 0) vai saglabāta (vārtu izeja = 1).
2. attēlā mēs redzam LSTM vienības tīkla struktūru. Katrai LSTM vienībai ir trīs vārti. Sākumā “aizmirst vārtu slāni” filtrē informāciju no iepriekšējā šūnas stāvokļa C (t − 1) pamatojoties uz pašreizējo ievadi x (t) un iepriekšējās šūnas slēptais stāvoklis h (t − 1). Pēc tam “ieejas vārtu slāņa” un “tanh slāņa” kombinācija izlemj, kuru informāciju pievienot iepriekšējam, jau filtrētam, šūnu stāvoklim C (t − 1). Visbeidzot, pēdējie vārti, “izejas vārti”, izlemj, kuru no atjauninātās šūnas stāvokļa informāciju C (t) nonāk nākamajā slēptajā stāvoklī h (t).
Lai iegūtu sīkāku informāciju par LSTM vienībām, skatiet GitHub emuāra ierakstu “Izpratne par LSTM tīkliem”, kuru sagatavojis Kristofers Olah.
2. attēls. LSTM šūnas uzbūve (atveidots no Ian Goodfellow, Yoshua Bengio un Aaron Courville “Deep Learning”). Ievērojiet trīs vārtus LSTM vienībās. No kreisās uz labo: aizmirst vārti, ieejas vārti un izejas vārti.
LSTM vienības ir veiksmīgi izmantotas daudzās laikrindu prognozēšanas problēmās, bet jo īpaši runas atpazīšanā, dabiskās valodas apstrādē (NLP) un bezmaksas ģenerēšanā.
Ģeneratīvie sacensību tīkli (GAN)

Ģeneratīvo sacīkstes tīklu (GAN) veido divi dziļi mācīšanās tīkli - ģenerators un diskriminētājs.
Ģenerators G ir transformācija, kas pārveido ieejas troksni z par tenoru - parasti attēlu - x (x= G (z)). DCGAN ir viens no populārākajiem ģeneratoru tīkla dizainiem. CycleGAN tīklos ģenerators veic vairākas transponētas konvolūcijas, lai palielinātu paraugu z lai beidzot izveidotu attēlu x (3. attēls).
Ģenerētais attēls x pēc tam tiek ievadīts diskriminatoru tīklā. Diskriminējošais tīkls pārbauda mācību komplekta reālos attēlus un ģeneratoru tīkla ģenerēto attēlu un rada izvadi D (x), kas ir šī attēla varbūtība x ir īsts.
Gan ģenerators, gan diskriminants tiek apmācīti, lai iegūtu reproducēšanas algoritmu D (x)=1 ģenerētajiem attēliem. Abi tīkli tiek apmācīti mainīgos soļos, sacenšoties, lai uzlabotu sevi. GAN modelis galu galā saplūst un rada attēlus, kas izskatās reāli.

GAN ir veiksmīgi piemēroti attēlu sensoriem, lai izveidotu anime, cilvēku figūras un pat van Gogam līdzīgus šedevrus. (Par citiem neironu tīklu mūsdienu lietojumiem skatiet 6 lielus sasniegumus, ko varat attiecināt uz mākslīgiem neironu tīkliem.)
Secinājumi
Tātad, vai dziļa apmācība ir tikai steroīdu neironu tīklu kopums? Daļēji.
Lai arī nav noliedzams, ka ātrākas aparatūras veiktspējas lielā mērā ir veicinājušas sarežģītāku, daudzslāņu un pat atkārtotu neironu arhitektūru veiksmīgu apmācību, tomēr ir arī taisnība, ka ir ierosināti vairāki jauni inovatīvi neironu mezgli un arhitektūras. tagad sauc par dziļo mācīšanos.
Jo īpaši mēs esam identificējuši konvolucionāros slāņus CNN, LSTM vienībās un GAN kā dažus no nozīmīgākajiem jauninājumiem attēlu apstrādes, laikrindu analīzes un bezmaksas ģenerēšanas jomā.
Vienīgais, kas šajā brīdī ir jādara, ir padziļināties un uzzināt vairāk par to, kā dziļi mācīšanās tīkli var mums palīdzēt ar jauniem, stabiliem risinājumiem mūsu pašu datu problēmām.